Сжатие данных широко используется в самых разнообразных контекстах программирования. Все популярные операционные системы и языки программирования имеют многочисленные инструментальные средства и библиотеки для работы с различными методами сжатия данных.
Правильный выбор инструментальных средств и библиотек сжатия для конкретного приложения зависит от характеристик данных и назначения самого приложения: потоковой передачи данных или работы с файлами; ожидаемых шаблонов и закономерностей в данных; относительной важности использования ресурсов ЦП и памяти, потребностей в каналах передачи и требований к хранению и других факторов.
Машинное обучение с каждым днем занимает всё большее место в нашей жизни ввиду огромного спектра его применений. Начиная от анализа пробок и заканчивая самоуправляемыми автомобилями, всё больше задач перекладывается на самообучаемые машины.
Существующие методы машинного обучения в зависимости от степени автоматизации поиска решений поставленной задачи, по мнению доктор наук Yoshua Bengio можно разделить на 4 типа: rule-based systems (экспертные системы, основанные на базе знаний); classic machine learning (классические алгоритмы машинного обучения); representation learning (обучение представлениям); deep learning (глубокое обучение).
Экспертные системы, основанные на базе знаний, обладают наименьшей степень автоматизации получения решения поставленной задачи. В этом случае качество работы такой системы зависит только от мастерства программиста, инженера по знаниям и эксперта (источника экспертных знаний). Алгоритмы глубоко машинного обучения наоборот обладают высокой степенью автоматизации при работе с данными. Такие алгоритмы самостоятельно анализируют исходные данные, выделяют существенные признаки данных, вырабатывают стратегию решения поставленной задачи. Классические алгоритмы машинного обучения и обучение представлениям обладают средней степенью автоматизации при работе с данными.
В настоящее время проводятся исследования по повышению степени автоматизации алгоритмов машинного обучения. Например, на начальном этапе своего развития нейронные сети нейронные сети с малым количеством слоев относились к классическим алгоритмам машинного обучения. Однако с увеличением количества вычислительных слоев и совершенствованием способов их обучения стали появляться конфигурации нейронных сетей, относящихся к глубокому обучению.
Целью этой работы - изучение теоретических вопросов машинного обучения на основе сжатия данных.
Для достижения поставленной цели необходимо изучить понятие сжатия данных, его алгоритмы
1 Анализ состояния вопроса
1.1 Проблемы развития алгоритмов машинного обучения
Понятию машинное обучение (Machine Learning) существует множество определений. Наиболее часто используемое определение говорит, что это множество методов, особенностями которых является решение задач не напрямую, а обучение решению текущей задачи на примере множества сходных задач. В разработке методов машинного обучения используются средства математической статистики, различные численные методы, а также методы оптимизации и вероятностные подходы. В настоящее время с усложнение методов машинного обучения стали наборы алгоритмов относящихся к классу глубокое обучение (Deep Learning). Основным отличие данного класса алгоритмов от классических методов машинного обучения является, то, что их работа основана на изучении множества уровней представлений (множество уровней абстракций). Т.е. алгоритмы глубоко обучения, позволяют определять объекты сложной конфигурации на основе данных различных уровней абстракции.
На основании выше сказанного доктор наук Yoshua Bengio в своём учебном курсе под названием Deep Learning: Theoretical Motivations предлагает следующую классификацию алгоритмов машинного обучения (рисунок 1.1).
На рисунке 1.1 показано взаимодействие уровней абстракций для четырех типов множеств методов машинного обучения: rule-based systems (экспертные системы основанные на базе знаний); classic machine learning (классические алгоритмы машинного обучения); representation learning (обучение представлениям); deep learning (глубокое обучение).
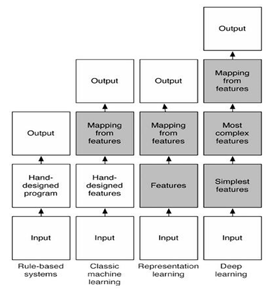
Рисунок 1.1 – Классификация алгоритмов машинного обучения, предложенная Yoshua Bengio
Необходимо отметить, что на схеме (рисунок 1.1) серым цветом выделены блоки, способные (без вмешательства человека) обучаться по имеющимся данным. А белым цветом выделены блоки, которые человеку необходимо программировать и анализировать вручную.
Рассмотрим особенности экспертных систем (rule-based systems)
Экспертные системы, основанные на базе знаний, представляют из себя компьютерную программу. Причем, то как будет функционировать экспертная систем определяется человеком вручную. Поэтому, для создания экспертной системы ну жен эксперт из рассматриваемой области, который будет представлять из себя источник знаний и программист, который будет формализовывать эти знания в виде программного кода. Для того, чтобы сгенерировать ответ на поставленный вопрос, экспертная система использует факты, хранящиеся в базе знаний с учетом правил логических правил.
Рассмотри особенности классического машинного обучения (classic machine learning).
При построение программ с использование классических алгоритмов машинного обучения наиболее важные указания вводятся человеком вручную. Но при этом программа самостоятельно обучается на основе входных признаков определять требуемое решение. Данный класс машинного обучения может решать задачи распознавания простых объектов. При создании интеллектуальных систем, основанных на использовании данного типа машинного обучения, наиболее трудоемкими являются задачи подбора обучающей выборки и определение наиболее удачного сочетания параметров используемого метода.
Рассмотрим особенности обучения представлениям (Representation Learning). Если сравнивать классические методы машинного обучения и обучениям представлениям, то последние являются более автоматизированными, т.к. избавляют от необходимости формализации знаний экспертов. Поиск значимых закономерностей в этом случае осуществляется автоматически на основании предъявленной человеком обучающей выборке.
Рассмотрим особенности глубокого обучения (Deep Learning). Методы глубоко обучения отличаются от других методов, что входные данные анализируются на нескольких уровнях абстракции. На самом нижнем уровне в результате анализа данных выделяются простые признаки, на следующем уровне производится анализ простых признаков с целью выделения более сложных признаков и т.д. до самого верхнего уровня абстракции.
Ярким представителем методов глубокого обучения являются сверхточные нейронные сети, которые применяются для поиска объектов изображениях. Такая нейронная сеть является многослойной. Каждый слой, в данном случае, отвечает за свой уровень абстракции. Слои, близкие ко входам нейронной сети отвечают за поиск простых признаков присутствия объекта на изображении, слои близкие к выходам нейронной сети отвечают за анализ простых признаков с целью формирования вывода о присутсвии искомого объекта на изображении.
Исследователи искусственного интеллекта отмечают три основных компонента необходимые для его создания:
- Наличие огромных объемов данных.
- Использование гибких моделей для их анализа.
- Наличие априорных знаний.
Таким образом, для создания систем искусственного интеллекта требуется большое количество знаний. Для формализации знаний из имеющихся данных на раннем этапе развития искусственного интеллекта применялся человеческий труд. Сейчас с этой задачей успешно справляются алгоритмы машинного обучения. Знания необходимы, чтобы система искусственного интеллекта могла принимать верные решения в любых ситуациях.
Наличие априорных знаний позволяет частично решить проблему большого размера избыточных знаний. Для этого системе искусственного интеллекта сообщаются только те априорные знания, которые необходимы для решения возложенных на нее задач.
Непараметрические методы умеют работать с большими объемами данных, обдают достаточно гибкими моделями, однако их использование требует обеспечение процедуры сглаживания данных.
Для того, чтобы искусственный интеллект начал понимать окружающую обстановку в него необходимо вложить знания об мире. Основная проблема заключается в то, что существующие методы машинного обучения не позволяют хранить в себе такой объем знаний.
Тем не менее, все алгоритмы машинного обучения объединяет общая особенность – обучаемость. Это означает, что на основе данных частных случаев алгоритмы машинного обучения самостоятельно могут получать знания.
Также алгоритмы машинного обучения обладают способностью общения. Это означает, что они способы определять, какой результат является наиболее вероятным при данном наборе входных сигналов. Например, с точки зрения кластеризация – это предсказывание центра масс кластеров.
Одной из проблем практического применения алгоритмов машинного обучения является большая размерность вектора входных сигналов, к которая приводит к повышению сложности функций, необходимых для обобщения данных обучающей выборки. При количестве элементов вектора входных сигналов, равном двум – количество вариантов конфигураций обещающих функций значительно. Если количество элементов вектора входных сигналов больше двух, то даже просто посчитать количество возможных конфигураций обещающих функций затруднительно.
Другой проблемой алгоритмов машинного обучения является понимание данных. Так классические алгоритмы машинного обучения манипулирует данными, как обычными числами, не задумываясь о природе их появления. В этом отношении алгоритмы глубокого обучения делают шаг навстречу к пониманию программой природы данных.
В теории искусственного интеллекта в понятие непараметрических моделей вкладывается иной смысл, нежели в математическом моделировании. Здесь алгоритм машинного обучения называется непараметрическим, если сложность функций, которые он способен изучить, растет с ростом объема обучающей выборки (т.е. размерность вектора входных сигналов не является фиксированной).





